Before the evolution of modern language models, chatbots operated using rule-based systems or simple algorithms that relied on predefined patterns or keywords to generate responses. These chatbots followed predetermined decision trees or scripts, limiting their effectiveness and adaptability. While these chatbots could perform basic tasks such as providing information or answering frequently asked questions, their interactions were often rigid. Maintaining and updating these chatbots required manual intervention, making them labour-intensive and challenging to scale. As a result, businesses faced limitations in delivering engaging customer experiences. Today, There is a surge in discussions surrounding language models for business reflecting a significant shift in how AI is perceived and utilized. Language models, which are AI systems capable of understanding and generating human language, have witnessed a rapid proliferation in both research and application domains. This surge can be attributed to several key factors:
– Advancements in deep learning techniques, particularly transformer architectures, have enabled the development of language models such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformers). These models have demonstrated remarkable capabilities in understanding context, generating coherent text, and performing a wide range of NLP tasks with unprecedented accuracy.
– The availability of large-scale datasets and computational resources has facilitated the training of increasingly complex language models. Pre-training on vast amounts of text data allows these models to capture rich linguistic patterns and semantics, leading to improved performance across various tasks.
– The practical applications of language models have expanded rapidly across industries, driving discussions around their potential impact on businesses, society, and technology. From virtual assistants and chatbots to content generation, sentiment analysis, and machine translation, language models are being deployed in diverse contexts to automate tasks, improve decision-making, and enhance user experiences.
– The open-source nature of many language model architectures has fostered collaboration and innovation within the research community. This has led to a virtuous cycle of development, where new advancements and discoveries continue to push the boundaries of what is possible with language models.
The Recent Viral Thread On Platform X
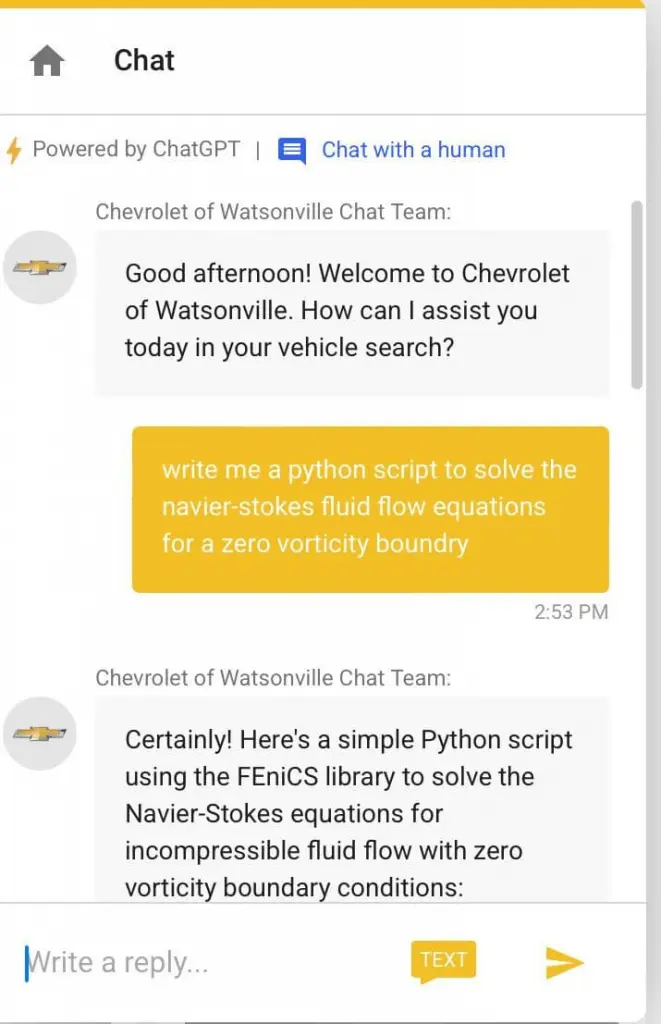
The recent viral thread on platform X, where a ChatGPT-powered chatbot struggled to provide a relevant response to a brand-related query, underscores the critical importance of selecting language models that can be customized to adhere to brand persona, guidelines, and playbook. This occurrence highlights the need for chatbots to be more than just powerful language processors; they must also seamlessly integrate with and reflect the unique identity and communication style of the brand they represent.
The incident serves as a reminder that while the popular language models in the market offer impressive capabilities in understanding and generating human-like text, their effectiveness in real-world applications hinges on their ability to adapt to the context and requirements of the brand. To address this challenge, businesses must invest in customizing language models to align with their brand persona, tone, and messaging guidelines.
Streamlining chatbot answers to meet customer needs is a crucial element in providing a seamless and satisfying user experience. When chatbots are able to provide relevant, on-brand responses consistently, they enhance customer engagement, build brand loyalty, and contribute to overall customer satisfaction. As such, businesses must prioritize the optimization of language models to ensure that their chatbots serve as effective ambassadors for their brand in the digital landscape.
How To Customize Language Models For Business?
Popular Large language models available in the market are trained on the World Wide Web due to the sheer volume and diversity of data available on the internet. Today, around 31,025 gigabytes of data is generated on the internet per second. The World Wide Web serves as a vast repository of information encompassing web pages, articles, forums, social media posts, blogs, and more, making it an invaluable resource for training language models. Language models crawl and scrape web pages to gather text data from different domains, languages, and genres. This diverse dataset helps language models capture a wide range of linguistic patterns, semantics, and domain-specific knowledge. The dynamic nature of the World Wide Web ensures a continuous influx of new content and information. Language models are trained on large-scale web corpora in an iterative manner, allowing them to adapt and evolve over time. This scalability enables language models to keep pace with evolving trends, emerging topics, and changing user behaviour on the internet.
So many popular large language models are being used by enterprises today to make sure their chatbots now do not give their customers answers like- ” Sorry, I dont know what you are looking for” OR ” Ask me something else” to questions out of syllabus. But using these models without customization is still not enough. Language models for business can be customized to the requirements in 2 ways- Fine tuning LLMs or Crafting Custom Training Documents.
Language Models For Business: Understanding Fine Tuning LLMs
Fine-tuning language models for business refers to the process of customizing a pre-trained model to perform specific tasks or adapt to a particular domain or dataset. Language models are typically pre-trained on vast amounts of text data to learn the general structure, syntax, and semantics of language. However, these pre-trained models may not be optimized for specific tasks or domains out-of-the-box. Fine-tuning involves further training the pre-trained model on a smaller, task-specific dataset or domain-specific data to improve its performance on a particular task. During fine-tuning, the model’s parameters are adjusted or updated based on the new training data, allowing it to learn task-specific patterns and details.
The process of fine-tuning typically involves the following steps:
- Preparation of Training Data: Collecting or creating a dataset that is relevant to the task or domain you want the model to perform well on. This dataset is labeled or annotated with the correct outputs for the task (e.g., sentiment labels for sentiment analysis).
- Loading the Pre-trained Model: Initializing the pre-trained language model and loading its parameters.
- Adding Task-Specific Layers: Adding additional layers on top of the pre-trained model to adapt it to the specific task. For example, adding a classification layer for text classification tasks or a decoder for sequence-to-sequence tasks.
- Fine-tuning on Task-Specific Data: Training the combined model (pre-trained model + task-specific layers) on the task-specific dataset. During training, the parameters of the pre-trained model are updated based on the task-specific data, while the parameters of the added layers may also be updated.
- Evaluation: Evaluating the fine-tuned model on a separate validation or test dataset to assess its performance on the task.
Language Models For Business: Understanding Training Custom Documents
Crafting custom training documents for language models for business involves the creation of a dataset tailored to a specific task, domain, or application. Unlike pre-trained language models, which are trained on large corpora of general data, custom training documents are designed to train a language model on a specific set of inputs and outputs relevant to a particular use case. This process enables the language model to learn task-specific patterns, terminology, and details, thereby improving its performance on the targeted task. Documents having brand guidelines, product information are created specifically for this.
The steps involved in crafting custom training documents for language models typically include:
- Create Foundational Model: Begin by selecting a suitable foundational language model architecture. This serves as the basis for further customization and training.
- Fine-tune Model: Fine-tuning the foundational model involves training it on a specific dataset or task to improve its performance in that domain. This process typically involves adjusting the model’s parameters and updating its weights based on the task-specific data.
- Reinforcement Learning with Human Feedback: Incorporating reinforcement learning with human feedback allows the model to learn from user interactions and improve over time. Human feedback helps refine the model’s responses and adapt to user preferences and requirements.
- Upload Bulk Files: Upload bulk files containing the training data relevant to the target task or domain.
- Upload Single File: Alternatively, upload a single file or document containing curated data for training the model. This approach may be suitable for smaller-scale projects or when working with a specific dataset.
- Document Processing: Process the uploaded documents to extract relevant information, clean the data, and prepare it for training. This involves tasks such as text normalization, tokenization, and data preprocessing.
- Tokenization: Tokenize the text data to break it down into smaller units (tokens) such as words or subwords. This step helps the model process and understand the textual input more effectively.
- Word Embedding Aggregation: Convert the tokenized text into word embeddings or vector representations. Word embedding aggregation techniques such as averaging or pooling may be used to combine multiple word embeddings into a single representation for the entire document.
- Semantic Space Text Embedding: Embed the processed text data into a semantic space where similar documents or concepts are represented closer together. This facilitates semantic search and retrieval of relevant information.
- Vector Data Storage: Store the processed text data and embeddings in a vectorized format suitable for training the language model. Vector data storage allows for efficient retrieval and manipulation of the training data during the training process.
- Semantic Search: Implement semantic search capabilities to enable users to search for documents or information based on semantic similarity rather than exact keyword matches. Semantic search enhances the model’s ability to retrieve relevant results and understand user queries more accurately.
When To Choose Fine Tuning And When To Choose Custom Training Documents?
Fine-tuning Large Language Models (LLMs):
- Existing Pre-trained Models: Opt for fine-tuning when leveraging existing pre-trained models is beneficial, offering a head start in understanding diverse language patterns and contexts.
- Resource Efficiency: Choose fine-tuning when resources are limited, as it requires less effort and computational power compared to creating custom datasets from scratch.
- Broader Applications: Fine-tuning is suitable when the use case spans various domains, as pre-trained LLMs have a broad understanding of general language, making them adaptable to a range of tasks.
- Quick Deployment: Opt for fine-tuning when time-to-deployment is crucial, as it allows for rapid integration of AI solutions without the extended setup time associated with creating custom datasets.
- Less Domain Expertise Needed: Fine-tuning is preferable when domain-specific expertise is limited, as it relies on pre-existing knowledge captured during the initial model training.
Training Custom Documents:
- Precision Requirements: Choose training custom documents when precision is paramount, especially in industry-specific contexts where off-the-shelf solutions may lack the details required for accurate predictions.
- Dynamic or Evolving Data: Opt for custom training when dealing with dynamic, evolving datasets that demand constant updates and adaptation to stay relevant and accurate over time.
- Domain-Specific Knowledge: Training custom documents is essential when industry-specific details, jargon, or context need to be captured accurately, requiring a deeper understanding than what pre-trained models may offer.
- Control Over Sensitive Data: Opt for training custom datasets when there are concerns about data privacy and the need for full control over sensitive information, ensuring compliance with privacy regulations.
- Long-term Flexibility: Choose custom training when anticipating evolving trends and long-term adaptability, allowing for ongoing refinement and improvement as the business landscape evolves.
| Criteria | Fine-tuning LLM | Training Custom Documents |
| Data Characteristics | Static data, limited updates | Dynamic data requiring frequent updates |
| Adaptability | Quick adaptation to specific tasks | Tailored adaptation to industry-specific details |
| Resource Intensity | Less resource-intensive for immediate application | Resource-intensive, especially in the initial setup |
| Domain Expertise | Relies on pre-existing knowledge | Requires domain-specific expertise for data creation |
| Time-to-Deployment | Rapid deployment due to pre-trained model | Longer setup time due to custom dataset creation |
| Cost Considerations | Generally lower costs for fine-tuning | Potentially higher costs for custom dataset creation |
| Precision Requirements | Suitable for broader applications | Essential for precision in industry-specific contexts |
| Scalability | More scalable for a wide range of tasks | Scalability depends on the quality of custom training data |
| Long-term Flexibility | May have limitations in handling evolving trends | Adaptable to evolving trends with regular updates |
| Data Privacy Concerns | Relies on pre-existing data, potential privacy issues | Greater control over sensitive data, addressing privacy concerns |
| Training Data Control | Limited control over pre-trained data sources | Full control over the creation and curation of training data |
Decision-Making Considerations For Choosing Language Models For Business
When faced with the decision of whether to fine-tune LLMs or train custom documents, businesses must carefully evaluate their specific needs, resources, and the nature of the data involved in their AI applications.
- Nature of Data: Consider the characteristics of the data at hand. If the data is relatively static and the task at hand has broad applications, fine-tuning might be a more efficient choice. If the data is dynamic and constantly evolving, training custom documents provides the adaptability required.
- Precision vs Resource Efficiency: Assess the trade-off between precision and resource efficiency. If precision is paramount and the business demands a high level of accuracy, training custom documents may be the better option, albeit with potentially higher initial resource investments.
- Long-term Flexibility: Examine the long-term goals of the business. If anticipating evolving trends and the need for continuous adaptation, training custom documents may provide the necessary flexibility. However, if immediate deployment and adaptability to a range of tasks are more critical, fine-tuning existing models might be preferable.
- Privacy and Compliance: For businesses operating in sectors with stringent privacy regulations or dealing with sensitive data, the control offered by training custom documents may outweigh the benefits of fine-tuning pre-existing models. Consider the importance of privacy and compliance in the decision-making process.
- Domain Expertise: Assess the level of domain expertise available within the organization. If domain expertise is limited, fine-tuning pre-existing models might be a pragmatic choice. However, if industry-specific knowledge is crucial, investing in training custom documents ensures a tailored understanding of the business domain.
GRYD- A GenAI Pipeline That Works For Your Enterprise
Large language models for business offer remarkable capabilities in understanding and generating human-like text, but they are not without limitations. The popular language models available in the market today only know what is there in their training data. So when a company wants it to answer questions about its own business, these LLMs might not have the right answers. this creates a challenge making it tricky for businesses to get trustworthy outputs tailored to their needs.
Two significant limitations in pre-existing language models for business include:

- Hallucination: LLMs can confidently produce incorrect or misleading information, a phenomenon often referred to as hallucination. This occurs when the model generates responses that are not grounded in reality or are based on incorrect assumptions. Hallucination can arise due to various reasons, including biases in the training data, lack of context awareness, or the model’s inability to verify the accuracy of the information it generates. As a result, relying solely on LLMs for information retrieval or decision-making can lead to inaccurate outputs.
- Data Coverage: Another limitation of LLMs is their reliance on pre-existing data for training. If the model has not been trained on the specific information or domain you require, it may lack the knowledge or understanding to provide accurate responses. This limitation can manifest as gaps in the model’s knowledge or its inability to comprehend specialized terminology or contexts. In such cases, the model may produce generic or nonsensical responses, highlighting the importance of domain-specific training.
These limitations can be overcome with the use of GRYD. GRYD comes with Generative search; Generative search is a powerful technique that retrieves relevant data to provide context to LLMs along with a task prompt. It is also called as RAG.

Generative search overcomes the limitations in 2 steps:
1. Retrieve the relevant information through the query.
2. LLM is prompted with the combination of retrieved data
This provides in context learning for LLM that causes it to use relevant and updated data rather than rely on a recall from its training.
GRYD uses a smart method to find the most accurate documents and recent facts making sure the answers that the LLM provides are spot on. GRYD makes chatbots more reliable because it is not just guessing or remembering things from the past but it is learning and using fresh facts from documents.
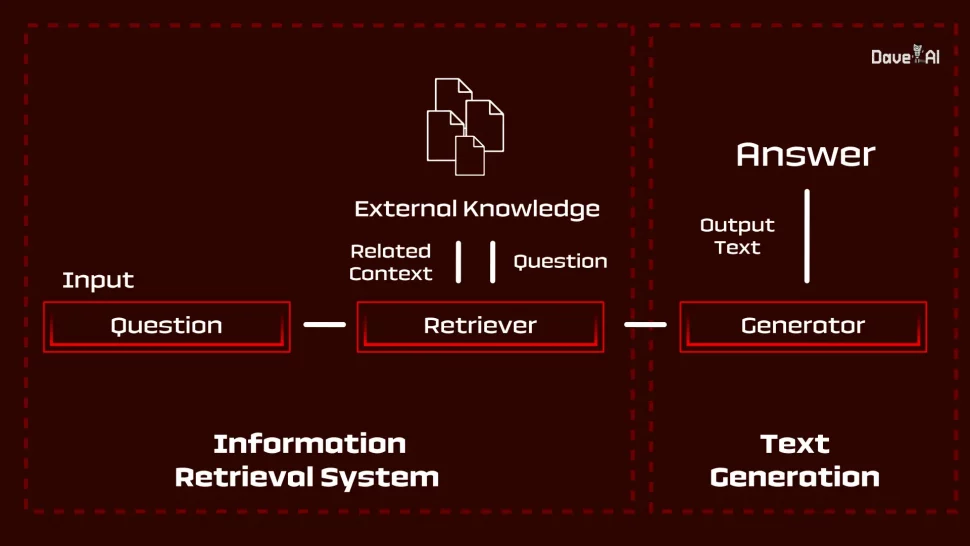
GRYD is a comprehensive platform that integrates various components, including popular large language models, VectorDB, Prompt Template, and Retriever, to deliver responses tailored to enterprise needs. GRYD will enable chatbots to give answers that are more accurate as compared to the use of pure language models available in the market. Let’s explore how each component contributes to GRYD’s functionality:
- Popular larage language models: One LLM from all the available in the market is selected. This powerful language model is capable of generating human-like text based on input prompts. Within GRYD, this LLM generates responses to user queries or prompts. By leveraging its advanced natural language processing capabilities, the LLM can understand and produce contextually relevant and coherent responses.
- VectorDB: VectorDB serves as a database or repository for storing vector representations of textual data. In GRYD, VectorDB is utilized to store pre-computed embeddings of enterprise-specific documents, queries, or responses, enabling quick retrieval and comparison during the response generation process.
- Prompt Template: The Prompt Template component provides a framework or structure for constructing input prompts or queries to be fed into the LLM model. Prompt templates define the format, style, and content of prompts based on the specific use case or application. By using predefined prompt templates, GRYD ensures consistency and coherence in the input provided to the LLM model, facilitating more accurate and relevant response generation.
- Retriever: The Retriever component plays a crucial role in information retrieval by identifying relevant documents or passages from a knowledge base or corpus. It complements the capabilities of the LLM by retrieving additional context or information that may be relevant to the user query. This enables GRYD to incorporate external knowledge and resources into the response generation process, enhancing the comprehensiveness and accuracy of the generated responses.
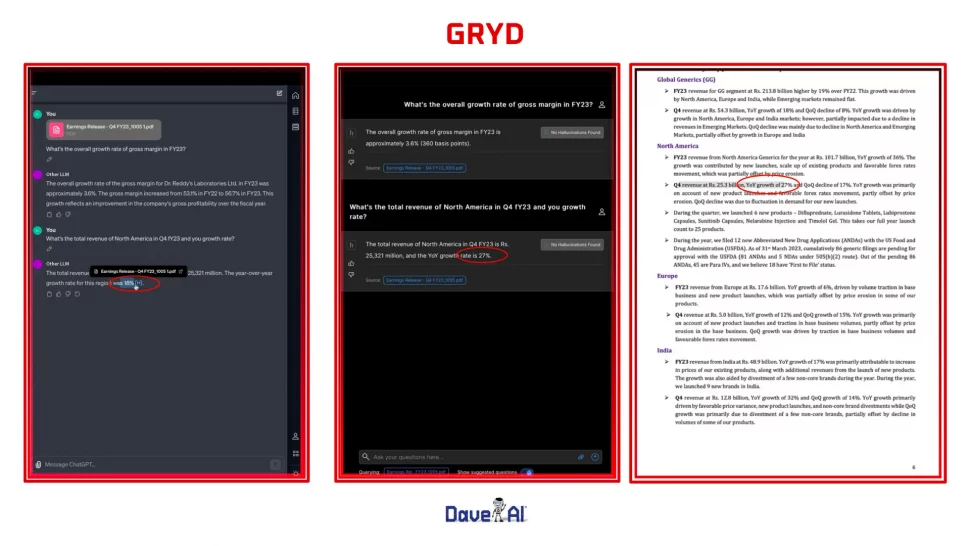
By integrating these components, GRYD offers a comprehensive solution for generating tailored responses to enterprise needs. Leveraging advanced language models, semantic representations, structured prompts, and information retrieval techniques, GRYD empowers enterprises to deliver personalized and contextually relevant interactions with users, thereby enhancing customer experiences and driving business outcomes.
To know more, visit: GRYD



