Water, water, everywhere, nor any drop to drink. That’s what information is like in today’s age. News articles, research, social media chatter, or corporate documents are plentiful and can act as treasure troves of data.
Yet, without a method to sift through this data, valuable insights remain buried. This is where Named Entity Recognition, or NER, steps in.
It lets you automatically extract pertinent information from vast amounts of text.
According to MarketsandMarkets, the global NLP market is set to surge from $18.9 billion in 2023 to $68.1 billion by 2028, growing at a robust CAGR of 29.3%.
But what exactly is Named Entity Recognition (NER) and why is it important?
Let’s discover.
What is Named Entity Recognition?

Named Entity Recognition is a core task in Natural Language Processing (NLP) that focuses on identifying and classifying named entities within textual data.
Imagine reading a news article and the important bits like the names of people, places, organizations, and dates, get magically highlighted for you. That’s the magic of Named Entity Recognition (NER).
Entities can be of many different types. These include:
- Person: Names of individuals (e.g., “Albert Einstein”).
- Organization: Names of companies or institutions (e.g., “GeeksforGeeks”).
- Location: Geographical entities (e.g., “Paris”).
- Date: Specific dates or time expressions (e.g., “5th May 2025”).
- Time: Specific times (e.g., “2:00 PM”).
- Money: Monetary values (e.g., “$100”).
- Percent: Percentage expressions (e.g., “50%”).
- Product: Names of products (e.g., “iPhone SE”).
- Event: Names of events (e.g., “Olympics”)
Do note that NER does not have to be limited to these. It can be tailored to recognize entities like medical codes in healthcare or legal terms in law.
But how does all this actually work?
At its core, NER transforms unstructured text into structured data by
- Tokenization: Breaking down text into words or phrases.
- Entity Detection: Identifying tokens that represent entities.
- Classification: Categorizing these entities into predefined types like Person, Organization, or Location
This sort of approach helps machines to understand text in a way that they can actually apply it, like in search engines or voice assistants.
NER can’t be lumped in with other NLP tasks. The differences rear their heads in the form of:
- Part-of-Speech (POS) Tagging: Assigns grammatical categories (like noun or verb) to words but doesn’t identify entities.
- Text classification: Categorizes entire documents, whereas NER focuses on specific elements within the text.
- Coreference resolution: Determines when different words refer to the same entity, complementing NER by linking pronouns to the entities they represent.
In essence, while other NLP tasks analyze the structure and meaning of text, NER zeroes in on extracting specific, meaningful entities.
How Named Entity Recognition Works
NER’s main focus is transforming unstructured text into structured data by identifying and classifying entities, as we discussed before. We had a quick look at the overarching way in which it works. However, there are multiple approaches to NER. Let’s dive deeper into the inner workings and understand them:
Rule-Based Approach
The rule-based approach mostly relies on pre-written and handcrafted rules and patterns that tell the system how it should identify the entities. These rules include:
- Regular Expressions: Patterns to match specific formats, like dates or phone numbers.
- Gazetteers: Lists of known entities, such as city names or company names.
- Linguistic Patterns: Utilizing part-of-speech tags and syntactic structures to identify entities.
This approach is perfect for when you want a very controlled environment. However, if you want scalability and adaptability, the rule-based approach struggles a lot.
Machine Learning Methods
Machine learning approaches to train models on annotated datasets to recognize entities. Common algorithms include:
- Decision Trees: Models that split data based on feature values to classify entities.
- Support Vector Machines (SVMs): Algorithms that find the optimal boundary between different entity classes.
- Conditional Random Fields (CRFs): Probabilistic models that consider the context of neighboring words for sequence labeling tasks.
The only drawback of this method is that it requires extensive feature engineering, such as identifying word shapes, prefixes, suffixes, and part-of-speech tags, to effectively learn from the data.
Deep Learning and Transformer-Based Approaches
Deep learning models, particularly those based on transformers, have revolutionized NER by automatically learning complex patterns from large datasets. Notable models include:
- Recurrent Neural Networks (RNNs): Suitable for sequential data but limited by vanishing gradients.
- Long Short-Term Memory Networks (LSTMs): A type of RNN that mitigates vanishing gradients, capturing long-term dependencies.
- Bidirectional LSTM (BiLSTM): Processes data in both forward and backward directions for better context understanding.
- Transformer Models: Such as BERT (Bidirectional Encoder Representations from Transformers), which use self-attention mechanisms to capture contextual relationships in text.
These models have achieved state-of-the-art results in NER tasks, particularly when fine-tuned on domain-specific data.
Evaluation Metrics for NER Models
Evaluating NER models involves assessing their ability to correctly identify and classify entities. Key metrics include:
- Precision: The proportion of correctly identified entities among all entities predicted by the model.
- Recall: The proportion of actual entities correctly identified by the model.
- F1 Score: The harmonic mean of precision and recall, providing a balance between the two.
These metrics can be calculated at different levels:
- Token-Level Evaluation: Assesses each word individually, which may not capture the full entity accurately.
- Entity-Level Evaluation: Considers the entire span of the entity, providing a more holistic assessment of the model’s performance.
Popular NER Algorithms and Models
Named Entity Recognition might seem like magic, but behind it are models—old, new, and cutting-edge—that work together to spot names, places, dates, and more. Each method, from statistical models to neural networks and transformers, has its strengths and quirks. Let’s break them down and see how they power NER.
Statistical Models: CRF and HMM
Early NER systems relied on statistical models like Hidden Markov Models (HMMs) and Conditional Random Fields (CRFs).
- Hidden Markov Models (HMMs): These are generative models that assume a probabilistic process for sequences, modeling the joint probability of observed and hidden states.
- Conditional Random Fields (CRFs): As discriminative models, CRFs focus on modeling the conditional probability of the target sequence given the observed data, often yielding better performance than HMMs in sequence labeling tasks.
While these models laid the groundwork for NER, they often require extensive feature engineering and struggle with capturing long-range dependencies in text.
Neural Networks in NER: BiLSTM-CRF
The integration of neural networks, particularly Bidirectional Long Short-Term Memory (BiLSTM) networks combined with CRFs, marked a significant advancement in NER.
- BiLSTM: Processes sequences in both forward and backward directions, capturing context from both sides.
- CRF Layer: Added on top of BiLSTM to model the dependencies between output labels, ensuring valid tag sequences.
This architecture has been effective in various domains. For instance, in Turkish NER tasks, a Word-Char-BiLSTM-CRF model achieved an F1 score of 91.84% on the test set.
Transformer Models: BERT, SpaCy, and Others
Transformer-based models have revolutionized NER by capturing contextual relationships more effectively.
- BERT (Bidirectional Encoder Representations from Transformers): Pre-trained on large corpora, BERT can be fine-tuned for NER tasks, achieving high accuracy.
- SpaCy: Offers pre-trained transformer-based pipelines like en_core_web_trf, which have shown strong performance in NER tasks.
In comparative studies, transformer models like BERT have demonstrated superior performance. For example, BERT-base-cased achieved an F1 score of 89.37% on the CoNLL-2003 dataset.
Performance comparison
Let’s take a look at what each of these models is best at and where they lack with the help of a table.
| Model Type | Strengths | Weaknesses | Performance Example |
| Statistical Models (CRF, HMM) | Clear, interpretable rules; good with feature engineering | Struggle with long-range context and complex language structures | F1 ~85% (depends on data) |
| Neural Networks (BiLSTM-CRF) | Capture context from both directions; balanced performance and computational cost | Can miss subtle nuances in complex contexts | F1 ~91.8% (Word-Char-BiLSTM-CRF on Turkish NER) |
| Transformer Models (BERT, SpaCy) | Strong contextual understanding; pre-trained on large datasets, high accuracy | Require more computational resources; less interpretable | F1 ~89.4% (BERT-base-cased on CoNLL-2003) |
Implementing NER: Tools and Libraries
When it comes to bringing Named Entity Recognition into your projects, you have plenty of options. From powerful open-source libraries to ready-made commercial APIs, and even the ability to customize models for your specific needs. Let’s explore the tools that make NER practical and accessible.
Open-Source NER Solutions
For those venturing into NER, several open-source libraries offer robust functionalities:
- spaCy: A popular Python library known for its speed and efficiency. It provides pre-trained models for various languages and supports custom model training.
- NLTK (Natural Language Toolkit): Offers basic NER capabilities and is excellent for educational purposes and prototyping.
- Flair: Built on PyTorch, Flair provides state-of-the-art NER models and allows easy integration of embeddings.
- Stanford NER: A Java-based library that uses Conditional Random Fields (CRF) for NER tasks.
Commercial NER APIs
For scalable and ready-to-use solutions, several commercial APIs are available:
- Google Cloud Natural Language API: Provides entity analysis with support for multiple languages.
- Amazon Comprehend: Offers real-time NER capabilities and can detect entities like people, places, and organizations.
- Microsoft Azure Text Analytics: Part of Azure Cognitive Services, it provides NER functionalities with high accuracy.
- IBM Watson Natural Language Understanding: Offers NER among other NLP features, suitable for enterprise applications.
These APIs are accessible through platforms like Eden AI, which aggregates multiple AI services.
Customizing Pre-Trained NER Models
Tailoring NER models to specific domains enhances their accuracy. Libraries like spaCy allow for fine-tuning pre-trained models:
- Data annotation: Use tools like Doccano to label your dataset with custom entities.
- Model training: Fine-tune spaCy’s models using your annotated data.
- Integration: Deploy the customized model into your application pipeline.
This approach is particularly beneficial for industries like healthcare or finance, where domain-specific entities are prevalent.Here’s a simple example of performing NER using spaCy:
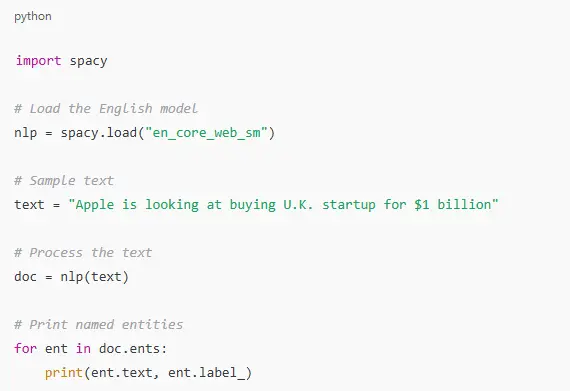
This script will output entities like “Apple” as an organization and “U.K.” as a geopolitical entity.
Real World Use Cases of NER
Let’s step out of theory and into the real world. NER is transforming industries and making sense of data-oceans with precision. Here are some real-world arenas where NER finds purchase:
Healthcare and Biomedical Applications
In healthcare, NER extracts critical data like patient names, medications, diseases, and treatments from medical records and research papers. This speeds up diagnosis, research, and personalized treatment plans. For example, NER helps analyze clinical notes to identify adverse drug reactions or detect disease outbreaks early.
Business Intelligence and Market Research
NER sifts through vast volumes of news, reports, and social media chatter to identify companies, products, and market trends. Businesses use this to monitor competitors, spot emerging opportunities, and tailor strategies with laser focus.
Legal Document Processing
Lawyers and paralegals wrestle with mountains of contracts, case files, and legislation. NER automates the extraction of parties’ names, dates, and legal terms, speeding up due diligence and contract review while reducing errors.
Customer Service Automation
Chatbots and virtual assistants rely on NER to recognize customer names, product names, and issue categories from conversations. This understanding allows them to respond accurately, personalize interactions, and escalate issues efficiently.
Content Recommendation Systems
By identifying entities such as authors, topics, or brands within content, NER helps recommendation engines suggest relevant articles, videos, or products, giving you a tailored experience that feels almost psychic.
Social Media Monitoring
Brands use NER to track mentions of their names, competitors, or events across social media platforms in real-time. This insight helps manage reputation, gauge public sentiment, and react swiftly to trends or crises.
Challenges in Named Entity Recognition
Named Entity Recognition is powerful, but it’s far from flawless. Let’s unpack some of the biggest hurdles NER has to overcome
Ambiguity in Entity Classification
Sometimes, the same word can wear many hats. Take “Apple”—is it a fruit, a company, or a music label? NER systems can struggle to pick the right meaning without enough context, leading to misclassification.
Domain-Specific Entity Recognition
Entities in medicine, finance, or law can be highly specialized. A general NER model might miss or mislabel terms that are everyday jargon in those fields. Customization is key, but it requires annotated data and extra effort.
Handling Emerging Entities
New names pop up constantly—think startups, slang, or trending topics. NER systems trained on older data may miss these fresh entries or fail to recognize their significance until retrained.
Multilingual NER Challenges
Languages differ widely in structure, grammar, and even writing systems. Building NER models that perform well across multiple languages—or switch seamlessly—adds a layer of complexity few tools handle perfectly.
Despite these challenges, ongoing research and advances keep pushing NER’s limits, making it smarter and more adaptable every day. Ready to see what the future holds?
Future Trends in NER
The future of Named Entity Recognition is looking really exciting. One big trend is zero-shot and few-shot learning. This means models can start recognizing new names or terms with very little training, saving time and effort.
Another big shift is multimodal NER, which combines text with images, videos, and audio. This helps models understand more complex data, like linking a news story with related pictures. We’re also seeing more self-supervised learning, where models teach themselves using huge amounts of unlabeled data. This makes NER more efficient and accurate.
Plus, combining NER with knowledge graphs means the system doesn’t just spot names—it connects them with other useful information. This can improve search engines, make recommendations more personal, and even make it easier to find answers from data.
If you want to jump on these trends and make sure your business doesn’t fall behind, you can always trust DaveAI to have your back. Talk to our experts to know more today.
The Power and Promise of NER
Named Entity Recognition isn’t just a niche technology—it’s a cornerstone of modern natural language processing. From identifying names and dates to connecting ideas across text, NER transforms raw data into actionable insights.
Whether it’s helping doctors pull critical details from medical records or giving businesses the edge in understanding market trends, NER has proven itself a valuable tool.
If you’re thinking of diving in, there’s no shortage of resources. Open-source libraries like SpaCy and Hugging Face Transformers make it easy to get started, while commercial APIs offer ready-to-use solutions for quick wins. With ongoing advancements, from self-supervised learning to multimodal NER, the technology is only going to get smarter and more adaptable.
As we move forward, NER will continue to evolve, breaking language barriers and tackling more complex challenges. It’s a thrilling time for this technology, and for anyone ready to explore it, the possibilities are endless.
FAQ
NER identifies and categorizes specific elements in text, such as names of people, places, dates, and organizations. It helps turn unstructured text into structured data.
NER focuses on finding and classifying entities in text, while sentiment analysis focuses on understanding the emotional tone or opinion behind the text. They often complement each other in applications like customer feedback analysis.
Yes, but it’s challenging. NER models are typically trained on specific languages. To handle multiple languages, you need models with multilingual capabilities or customized training for each language.
Absolutely. You can fine-tune pre-trained models using industry-specific data. This is especially useful in fields like healthcare, law, and finance, where entity types and terminology are highly specialized.
Generally, yes, especially for deep learning models. However, recent advancements in few-shot and self-supervised learning are making it possible to achieve strong results with less labeled data.



