How many times have you wanted just to upload an image from a slide at the last second and have AI analyze it or create content for it? Sadly, a ton of AI models aren’t capable of achieving that. That’s where Vision Language Models come in.
They help you with the tasks we mentioned and find a ton more applications too. So, without further ado, let us jump into what VLMs are and how they are being utilized in multiple industries, and most importantly, how you can implement them for the growth of your business.
What Are Vision Language Models?
Vision Language Models (VLMs) are AI systems that combine computer vision and natural language processing (NLP) to understand and generate text from visual inputs like images and videos.
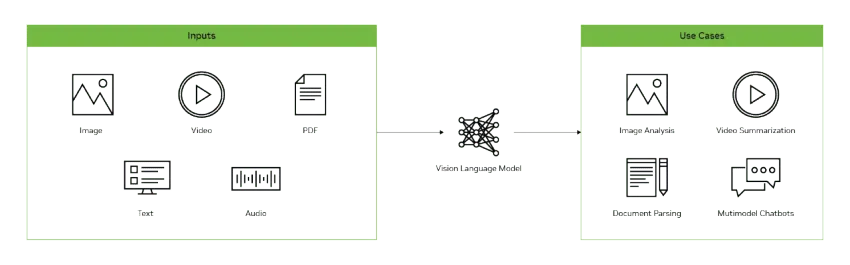
Using VLMs, you can achieve things like image captioning, visual question answering, and text-to-image generation. And those are just the most basic of uses.
At the heart of it, a VLM blends two powerful systems: computer vision (for seeing) and natural language processing (for understanding and generating text).
It’s trained using image-text pairs. Think of a photo of a dog with the caption “a golden retriever playing fetch.” Over time, the model learns how certain visuals relate to certain words. Eventually, it gets smart enough to describe a brand-new image or answer questions about it without needing to be explicitly told how.
This is part of the bigger AI shift you might’ve heard about, i.e., the multimodal revolution. Instead of treating images and language as two separate islands, VLMs bridge the gap. That’s what sets them apart from older, single-modality models that could only deal with one thing at a time.
Now let’s talk about what makes VLMs so special:
- They process both visuals and text at the same time
- They perform well even without task-specific training (zero-shot learning)
- They work across a wide range of tasks: image classification, question answering, OCR, and more
- They adapt easily to new domains and use cases
- They can understand and reason across formats: text, images, or a mix of both
In short, VLMs are making AI feel a lot more human. They see, they read, they respond.
How Do Vision Language Models Work?
So, what’s actually going on under the hood of a vision language model? It involves a smart design, a lot of training, and a bit of clever coordination between two very different kinds of data. Let’s break it piece by piece.
Architecture overview
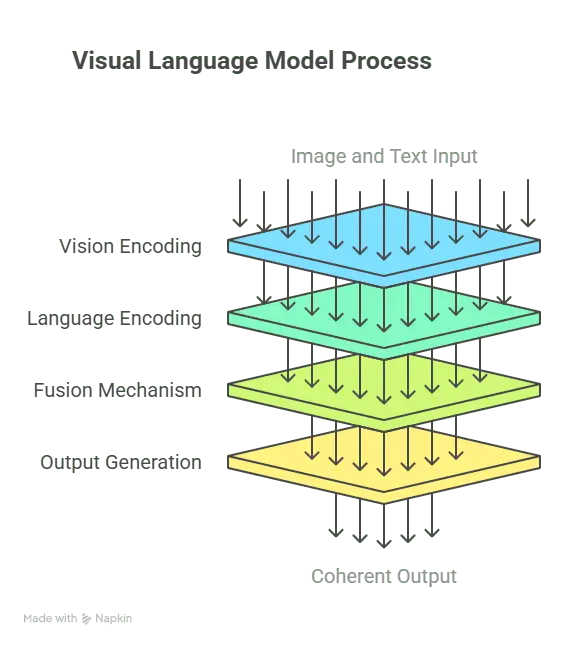
At the core of any VLM are two separate brains working in sync: one for images and one for words.
The vision encoder
On the visual side, you’ve got a vision encoder. This is usually built with a Convolutional Neural Network (CNN) or a Vision Transformer (ViT). Its job is to look at an image and break it down into meaningful patterns. It turns pixels into something a machine can understand and recognize over multiple iterations.
The language encoder
Then comes the language encoder, which is typically based on transformer architecture. It processes the text side of things, like generating captions, prompts, and questions. It understands grammar, context, tone, and all the subtle meanings behind words.
The fusion mechanism
But the real magic happens in between.
That’s where fusion mechanisms step in. These are attention layers that let the model connect the dots between what it sees and what it reads. For example, if the image shows a cat and the text says “a cat on a windowsill,” the fusion layer helps the model match “cat” in text to the actual cat in the photo.
Output generation
Finally, there’s the output generation process, where the model either generates a text (like a caption or answer) or chooses the most likely label from a list. It’s the part where understanding becomes action.
Popular VLM architectures and how they are trained
While the avenue is still a fledgling one, there have been many AI models that have begun to tackle it. Let’s look at a few models and how they can do what they do.
Contrastive learning
Imagine teaching a toddler what a cat is, not just by showing cats, but also by pointing out what isn’t a cat. That’s the basic idea behind contrastive learning.
At its core, contrastive learning is about teaching a model to tell the difference between things. Instead of just recognizing an object, the model learns by comparing—what makes a cat not a dog? How is a sneaker different from a boot?
This technique relies on something called contrastive loss, which pushes similar image-text pairs closer together in its internal representation space and pulls dissimilar ones apart.
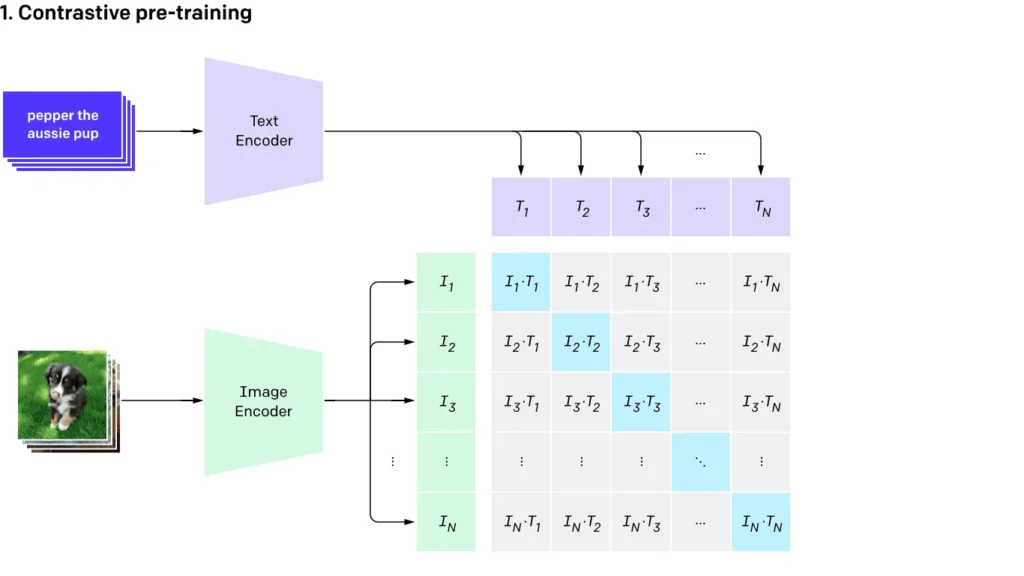
CLIP is the poster child here. It uses both an image encoder and a text encoder to process images and descriptions. During pretraining, it learns to match the right caption with the right image. Later, when you give it a new image, it doesn’t need fine-tuning. It just finds the best matching caption from its learned associations.
ALIGN is another model in this camp. It works similarly, training image and text encoders side by side to minimize the gap between matching embeddings.
This approach is perfect for zero-shot learning, where the model can perform tasks it was never directly trained for, simply by measuring semantic similarity
PrefixLM-based architectures
PrefixLM is a technique borrowed from language modeling. The model gets a prefix (part of a sentence) and learns to predict what comes next. When you combine this with an image, the model uses both the image and text prefix to generate the rest of the sequence.
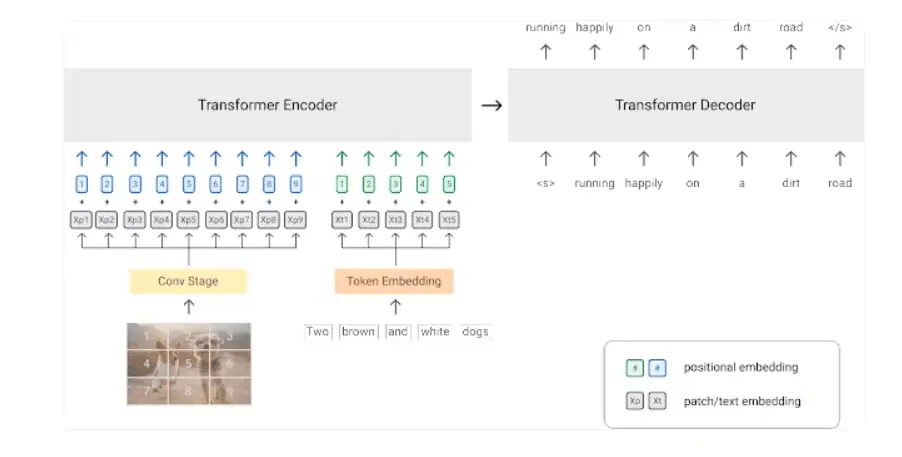
SimVLM runs with this method. It slices images into patches using a Vision Transformer and treats them like words. Then, it mixes those patches with text to create a unified representation, allowing it to generate fluent, relevant responses. It’s fast, effective, and great at generalization.
VirTex uses a slightly different setup. It starts with a convolutional network for images, passes the features to a transformer-based language model, and learns image-to-text mappings by predicting captions.
Frozen PrefixLM: minimal training, maximum flexibility
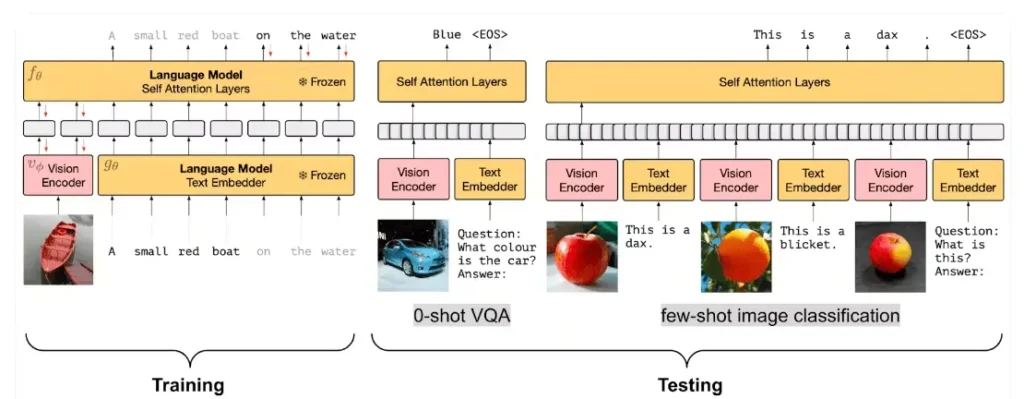
Frozen PrefixLM, as the name suggests, keeps most of the model frozen. Only the image encoder is fine-tuned. Flamingo follows this approach. It uses CLIP-style vision encoders and plugs them into a language model like Chinchilla. This setup allows fast few-shot learning with minimal training effort.
A unique module called the Perceiver Sampler helps extract key information from visual inputs efficiently. Since the text model stays frozen, training becomes faster and more stable, which is great for few-shot learning and quick deployment
Cross-attention architectures
Cross-attention introduces a more refined method for fusing images and text. Models like VisualGPT feed visual representations into a decoder that’s initialized with a pre-trained language model.
The decoder uses cross-attention layers to balance both modalities. This method also uses something called SRAU (Self-Resurrecting Activation Unit) to keep gradients flowing smoothly during training.
It’s all about making sure the visual features actually influence the generated text and that the system doesn’t “forget” the image halfway through.
Masked language modeling and image-text matching
VisualBERT blends two popular NLP techniques: MLM (Masked Language Modeling) and ITM (Image-Text Matching). It takes an image and a sentence with a missing word, then uses the visual context to guess the blank. It also learns to predict whether a sentence matches the image at all. It’s simple but powerful and built on the COCO dataset for training.
No training models
Some VLMs skip training altogether and just rely on large pre-trained models. MAGIC and ASIF are two examples.
MAGIC uses CLIP embeddings to guide a language model to produce descriptions that align well with images. ASIF does something clever too. It finds similar images in its dataset, looks at their captions, and then picks the caption that best matches the new image.
Knowledge distillation
Here, the model plays student and teacher. A large, powerful model teaches a smaller one how to perform. That’s the approach behind ViLD, which uses an open-vocabulary classification model as a teacher to train a two-stage object detector. It learns to draw boxes around objects in an image, even if those objects weren’t labeled during training.
Types and Categories of Vision Language Models
Not all VLMs are made the same. Some are designed to deliver results quickly, while others are meant to go deeper. Some VLMs can be run right on your laptop, while others need cloud support. So, let’s break it down by type, use, and how accessible they are.
By architecture type
- Encoder-only models: These models are built for fast interpretation. They don’t generate text but are great at matching images with descriptions. CLIP and ALIGN fall in this category. They process both the image and the text through encoders, then figure out how closely the two match.
Main uses: Search, classification, and filtering - Encoder-decoder models: These models can take an image, understand it, and generate a response. BLIP and Flamingo fall into this group. They use an encoder to process the image and a decoder to produce the output in natural language.
Main uses: Reasoning, summarizing, complex Q&A - Decoder-only models: These models, like GPT-4V and LLaVA, take in both text and images and generate rich, detailed responses. They use one multimodal decoder that does all the work.
Main uses: Interaction and conversation
By application focus
- General purpose VLMs: These are your all-rounders. They can caption, classify, answer questions, and more. GPT-4V, CLIP, and LLaVA are in this bucket. If you want a ton of flexibility and are not looking to build your own unique model, this is what you should be going for.
- Domain-specific VLMs: These models are trained for deep understanding in narrow fields. For example, in medical imaging, VLMs can read scans and explain findings. Others are tuned for scientific papers, legal documents, or industrial settings. If you work in a niche industry, these are for you. Businesses like DaveAI specialize in building these and other AI models for you, exactly according to your required specifications.
- Creative generation models: These models don’t just analyze the images; they actually create them. This includes models like DALL·E, Midjourney, and others that use visual inputs or prompts to generate entirely new images.
How Do You Measure VLM Capabilities: The Benchmarks
Evaluating the performance of Vision Language Models (VLMs) goes beyond measuring raw prediction accuracy. It’s about understanding how well the model links visual perception to linguistic understanding. Basically, how the VLM sees and talks about what it sees. There are two major ways of doing this:
Automated metrics: scoring text-image alignment
When testing tasks like image captioning, models are typically scored based on how closely their generated text matches human-written references. Several automated n-gram-based metrics are commonly used to do this:
- BLEU (Bilingual Evaluation Understudy): Calculates precision by comparing overlapping n-grams between the generated and reference text. It favors shorter, exact matches but can underweight semantic similarity.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Focuses on recall—how many of the reference n-grams appear in the candidate text. It’s especially helpful for summarization-style outputs.
- METEOR (Metric for Evaluation of Translation with Explicit Ordering): Strikes a balance between precision and recall, factoring in synonyms, stemming, and word order. It introduces a penalty for fragmentation, making it more linguistically aware than BLEU or ROUGE.
- CIDEr (Consensus-based Image Description Evaluation): Designed specifically for image captioning, this metric uses TF-IDF weighting to emphasize the consensus across multiple human references, promoting more descriptive and human-like captions.
Each metric brings its own strengths and biases, so a robust evaluation often involves a combination of them.
Vision-language benchmarks: testing general intelligence
Beyond captioning, a broader class of benchmarks has emerged to assess VLMs on complex multimodal tasks that span reasoning, memory, attention, and knowledge retrieval. These include:
- MMMU (Massive Multi-discipline Multimodal Understanding): Tests scientific and academic knowledge across disciplines, combining text, charts, and diagrams.
- Video-MME: Evaluates temporal reasoning by analyzing videos and answering related questions.
- MathVista: Assesses mathematical reasoning by posing math word problems grounded in images.
- ChartQA: Measures how well models can read and reason about charts and plots.
- DocVQA: Focuses on document-level visual question answering—reading scanned pages or forms and answering questions about them.
Applications of Vision-Language Models
Vision-Language Models (VLMs) are reshaping how you interact with technology. Here’s how you might be encountering their impact already:
- Image captioning and accessibility
VLMs automatically generate image captions that help users who are visually impaired understand visual content. If you browse the web or social media, these captions give you a clearer sense of what’s in an image without relying on sight alone. Google’s Lookout app and Chrome’s “Get Image Descriptions” feature are just two examples you might already be using.
- Visual question answering (VQA)
When you ask your phone something like, “What’s written on this sign?” or “Is this receipt for more than ₹500?” a VLM interprets both the image and the question. You’ll find this tech in educational tools, mobile assistants, and AI research platforms that help you get instant, intelligent answers from images.
Nearly 50% of e‑commerce searches now use Visual Question Answering (VQA), letting customers ask natural-language questions about product images and find what they need faster.
- Smarter product discovery in e-commerce
If you’ve ever uploaded a picture to find a product online or relied on auto-generated product descriptions, that’s a VLM at work. These models understand images of products and help you search more intuitively or read personalized, visually informed product summaries.
- Safer content moderation and customer service
Platforms like Instagram or YouTube use VLMs to catch policy-violating content, especially when images contain embedded text or context that’s hard to detect with traditional filters. That way, your experience stays safer and less cluttered with harmful or misleading posts.
Apart from service users by moderating content, we also notice that chatbots with embedded visual Q&A see adoption in 31% of enterprises, reducing response time and support costs.
- Automated quality control
45% of global manufacturers rely on computer vision for quality inspections, cutting defects, and eliminating manual checks. This is so prevalent that it’s even used in simple quality control measures like sorting good and bad tomatoes.
- Robotics
In robotics, VLMs help machines follow commands like “pick up the red cup next to the bowl” by combining visual input with text instructions. Whether you’re using a smart home device or an industrial robot on the floor, VLMs help those systems understand what you want, based on what they see.
In manufacturing, 30% of warehouse robots now use vision systems for item picking, improving efficiency by around 30%
- Medical imaging and report generation
Doctors and radiologists use VLMs to help summarize X-rays or annotate complex visuals. If you’re in healthcare, these models can speed up documentation and reduce errors by interpreting scans and generating clinical notes from them.
- Document parsing and data extraction
If you’ve scanned a form and needed to pull structured data from it, like a name, date, or total. VLMs help automate that process. They read, interpret, and extract insights from documents, charts, and handwritten notes, which makes tasks like tax filing or business reporting much easier.
- Autonomous driving and visual navigation
Self-driving cars rely on VLMs to read traffic signs, recognize pedestrians, and understand contextual cues. These models support real-time decisions by combining camera input with high-level reasoning, so when you ride in a smart vehicle, you’re trusting its ability to process both visual and verbal signals.
- Satellite imaging and space exploration
In space research, scientists use VLMs to interpret satellite imagery or even guide robotic systems during off-world exploration. These models help you analyze large visual datasets with minimal supervision, whether you’re tracking weather patterns or planning remote operations.
Expand Your Business With A Custom VLM
AI models are rapidly changing how businesses function. Companies like Maruti Suzuki, Hero MotoCorp, Wegofin, Kotak Mahindra Bank, and Jaquar are already using DaveAI’s varied AI models to make huge profits and headways.
Why should you lag behind? With DaveAI, create an AI model that suits your exact needs. Book a demo with our experts today.



